


Until you build a thing, you never truly know if it works. Simulations and theory are essential prerequisites, but experiment is where ideas are proven. For us, that presented a challenge: how can we build proof for a technology which demands cutting-edge silicon and requires significant capital?
We wanted to demonstrate that our architecture can crush inference latency, without asking people to take it on faith or to trust only in (very good) computer modelling. The answer was to separate out the core innovations at the heart of our architecture which do not rely on chip-scale implementation from those that do. We took these hardware-agnostic innovations and decided to build a system that would prove to ourselves and the outside world that not only do these ideas work, but they work fast.

The result is Babbage: our proof-of-concept optoelectronic system for ultrafast inference. It uses fibre optics with a mixture of bespoke analog and digital electronics to perform inference on a 4-neuron-wide, 3-layer-deep neural network in just 176 nanoseconds, faster than is possible on the latest GPU hardware Blackwell. This system let us verify two key innovations: Clockwork, our time-synchronisation system, and our ultrafast analog electronic Decision Engine.
Charles Babbage (1791–1871) was English inventor who designed the first programmable computer, the Analytical Engine. Like our proof-of-concept system, named in his honour, it contained a lot of mechanics.
Babbage implements a network with three layers of neurons, input, hidden, and output, and two linear layers in between them.
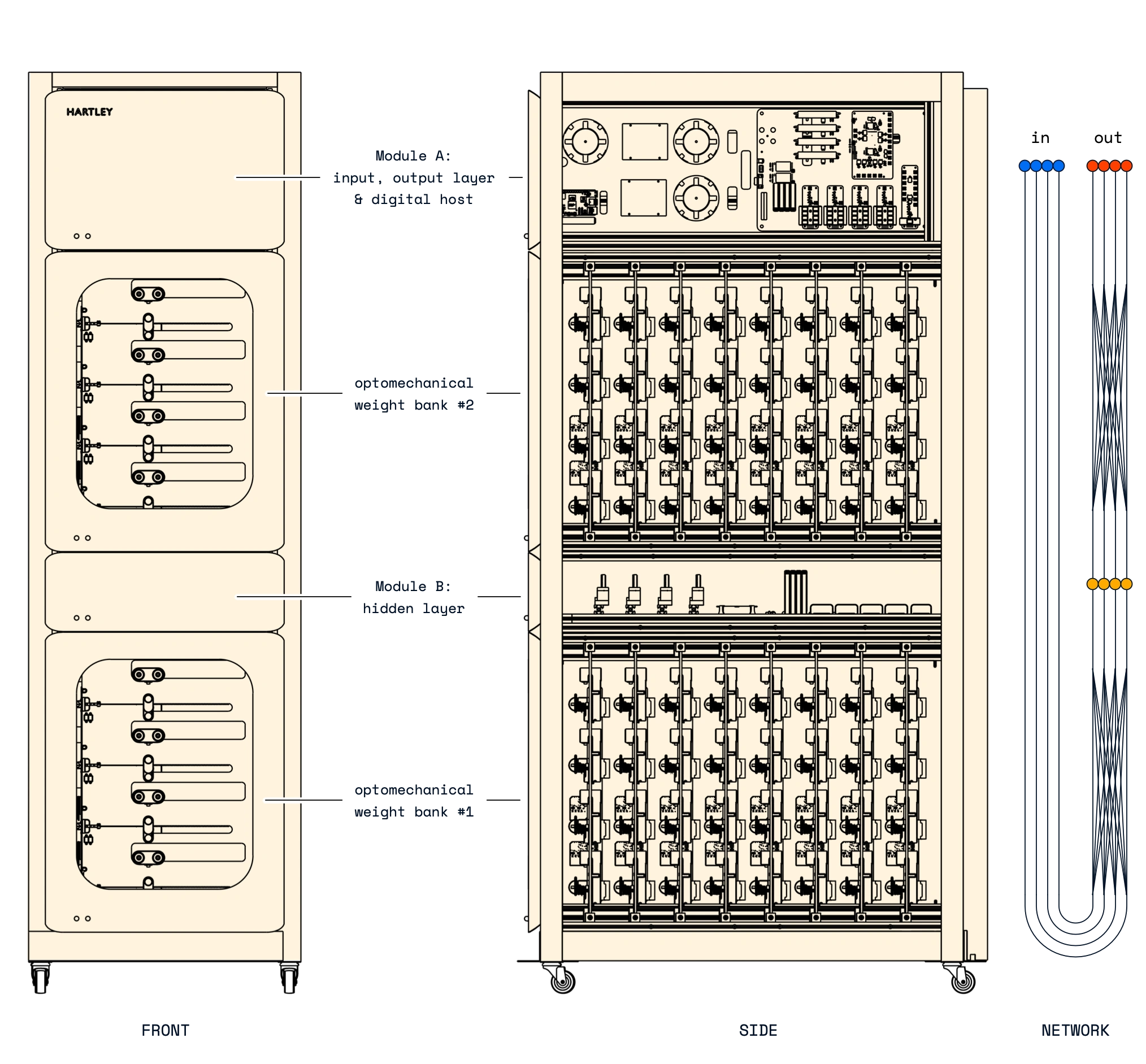
In the input layer, an embedded digital system puts inference queries into the optical domain, using four lithium niobate Mach-Zehnder modulators. These optical signals pass through the first optomechanical linear layer, consisting of 32 motorised fibre winders. Each winder tunes the optical loss, and a pair of them sets one weight matrix element, effectively multiplying the optical input signal by the winder's position. Taken together, the weights perform a 4×4 linear transformation between the input and hidden layers.
Within the hidden layer, the optical signals fan-in to each neuron, get converted to the electrical domain, then are synchronised and have neuronal nonlinear activation functions applied using our Clockwork technology. Four modulators then return the post-activations to the optical domain, and the second linear layer transforms them to produce the network's output signals. Clockwork again synchronises these and passes them to the Decision Engine, which returns ordinal data with extremely low latency. The embedded digital system then reads out the result.
Babbage is a fully functional neuromorphic system that uses, and proves, key parts of our architecture, but at a scale and cost that makes rapid experimentation possible.
With hardware in hand, the next challenge is obtaining models that will run on it.
Babbage belongs to a class of hardware called in-memory compute: rather than shuttling model data to and from memory, the model weights live directly in the physical fabric of the machine, and inference is simply the act of data passing through it. This is part of what makes inference so fast, but it also makes weight updates and training slow. Training with hardware in the loop would be time-consuming, but, more importantly, hardware-in-the-loop training would be a big pain for our customers.
Instead, we developed a digital twin using compact data from the hardware itself, and trained that. This unlocks all-digital, offline training, using standard machine learning tooling and workflows. With a trained digital model in hand, we upload the weights and biases to the hardware and run inference, without any other intervention. For customers, that means transparent model development and training processes with familiar toolchains, but with ultrafast, deterministic inference performance.
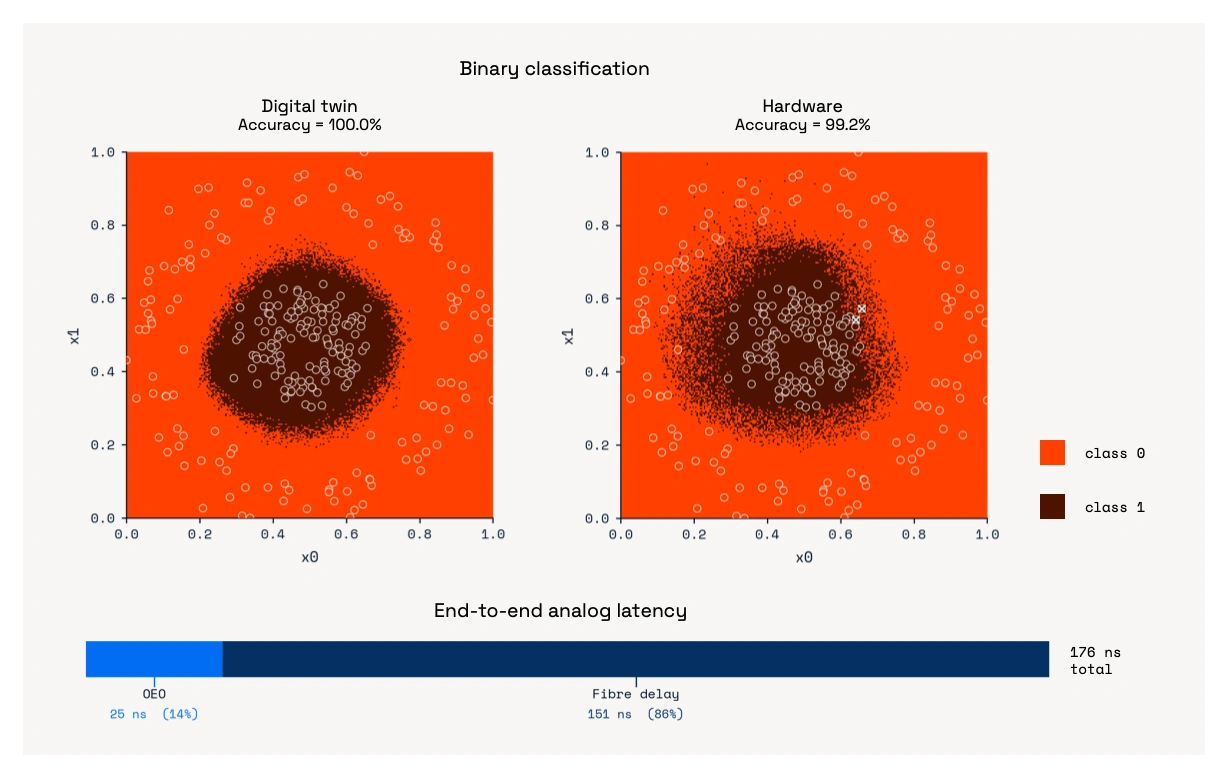
Figure 3 shows an example binary classifier trained entirely on the digital twin. Uploaded directly to Babbage with no retraining, the same model achieves 99.2% accuracy.
Accuracy is essential, but it is not the headline here. The special thing about Babbage is that it answers questions in just 176 nanoseconds, faster than is possible on the latest GPU hardware Blackwell. Figure 3 also shows a breakdown of Babbage's analog latency. Notably, almost all of that latency comes from propagation through optical fibre, not the optoelectronic processing itself.
For system designers used to working around millisecond or microsecond delays, this shift into the nanosecond regime changes what is possible for human-on-the-loop and algorithmic decision-making.
Babbage was built to validate our hardware-agnostic IP: our synchronisation system, Clockwork, and our ultrafast Decision Engine. The accuracy, with a model trained entirely digitally, confirms that Clockwork correctly handles the timing and that the Decision Engine provides a rapid, faithful ADC bypass for decision problems.
Babbage also demonstrates a key principle of low-latency inference: the optomechanical weights in Babbage are slow to move, but are fixed during operation. Computation happens at the speed of the electronic-photonic system, independent of motor movement. This is the core advantage of in-memory compute: the model is stored in place, while inference queries move through the system. In Babbage, motor positions store the model, and inference data effectively moves around at the speed of light.
So how fast can we move inference data in future?
Babbage gives us a clear answer. With the latency dominated by propagation in roughly 30 metres of fibre, the path is obvious: reduce propagation. On chip, integration with optical waveguides enables millimetre-scale paths, so propagation no longer dominates. Not only will chip-scale integration crush the inference latency even further, it will also let us massively scale up the supported model size.
Babbage is therefore both a proof of concept and a roadmap. It validates the core building blocks of Hartley’s architecture today, and it points directly to a future where ultrafast, optoelectronic neural processing units can be deployed alongside existing digital platforms to bring a new domain of speed to real-time, mission-critical intelligence.